
Volga - Streaming Engine and Networking - Deep Dive - Part 2
Designing a distributed networking stack for real-time high-throughput and low-latency streaming engine from scratch. Part 2.

TL;DR
This is the second part of a 3-post series about Volga's streaming engine and it’s networking stack.
The previous part has covered high-level streaming engine design, network topology and primitives and Python networking layer.
For scalability, performance, running Volga on 100+ CPU Kubernetes cluster and scaling to million messages per second see the third part.
For Volga's introduction and motivation see this post and for high-level architecture see this post.
In this part we will focus on low-level networking stack: Rust and ZeroMQ, Communication Protocol, Backpressure mechanics and more.
Content:
Brief Networking Technology Stack Overview
Small ZeroMQ Overview: what, why and how
Rust Networking Layer Overview (crossbeam channels, I/O threads, IOLoop, async comms)
Reliability Protocol (FIFO, ACKs, watermarks, retries, in-flight buffering)
Backpressure, shared channels and Credit-based Flow Control
A small personal note on development history
Brief Networking Technology Stack Overview
As mentioned in the previous post, Volga’s streaming engine is built using Ray Actors. Ray Actors have a built-in capacity for peer-to-peer communication, which is extremely useful when latency and throughput are not a concern e.g. reporting metrics/health status to a master actor, but not suitable to pass low-latency streaming data - Ray's Shared Object Store is not designed for this
Volga implements it's own networking stack using ZeroMQ for message passing between workers (Python processes), Rust layer for all low-level perf-critical network processing and PyO3 for a simple high-level Python interface for workers to easily pass data between each other in a reliable (no data loss) and FIFO (guaranteed ordering) manner while abstracting away all the low-level details.
Small ZeroMQ Overview: what, why and how
What? ZeroMQ is an asynchronous brokerless messaging library, aimed at use in distributed or concurrent applications. You can think of it as sockets on steroids: it's platform/language agnostic, handles a lot of low-level networking stuff for you and gives you lots of out-of-the-box building blocks to implement various messaging topologies without re-inventing the wheel. It has been used in lots of production applications, has extensive documentation/large community and even has books written about it. A notable example is Apache Storm - a streaming engine which uses ZeroMQ as it's messaging solution.
Why? When deciding on networking for a distributed messaging system another popular option is to use an RPC (Remote Procedure Call) framework. Why we chose ZeroMQ over RPC (gRPC, Arrow Flight):
Better performance. ZeroMQ is known to have a blazing fast perf w.r.t. to latency while gRPC adds noticeable overhead (HTTP stuff, frequent locking when number of peers/threads is high) and is known to show high tail latencies under high load.
Multi-transport. We want to be able to communicate between processes on same hosts as well as different hosts using the same API but different transport for better performance (IPC locally, TCP/UDP remotely). ZeroMQ easily allows that.
Simple API, no boilerplate. With gRPC, defining schemas using protobuf adds a lot of boilerplate, we wanted to easily pass schema-less data.
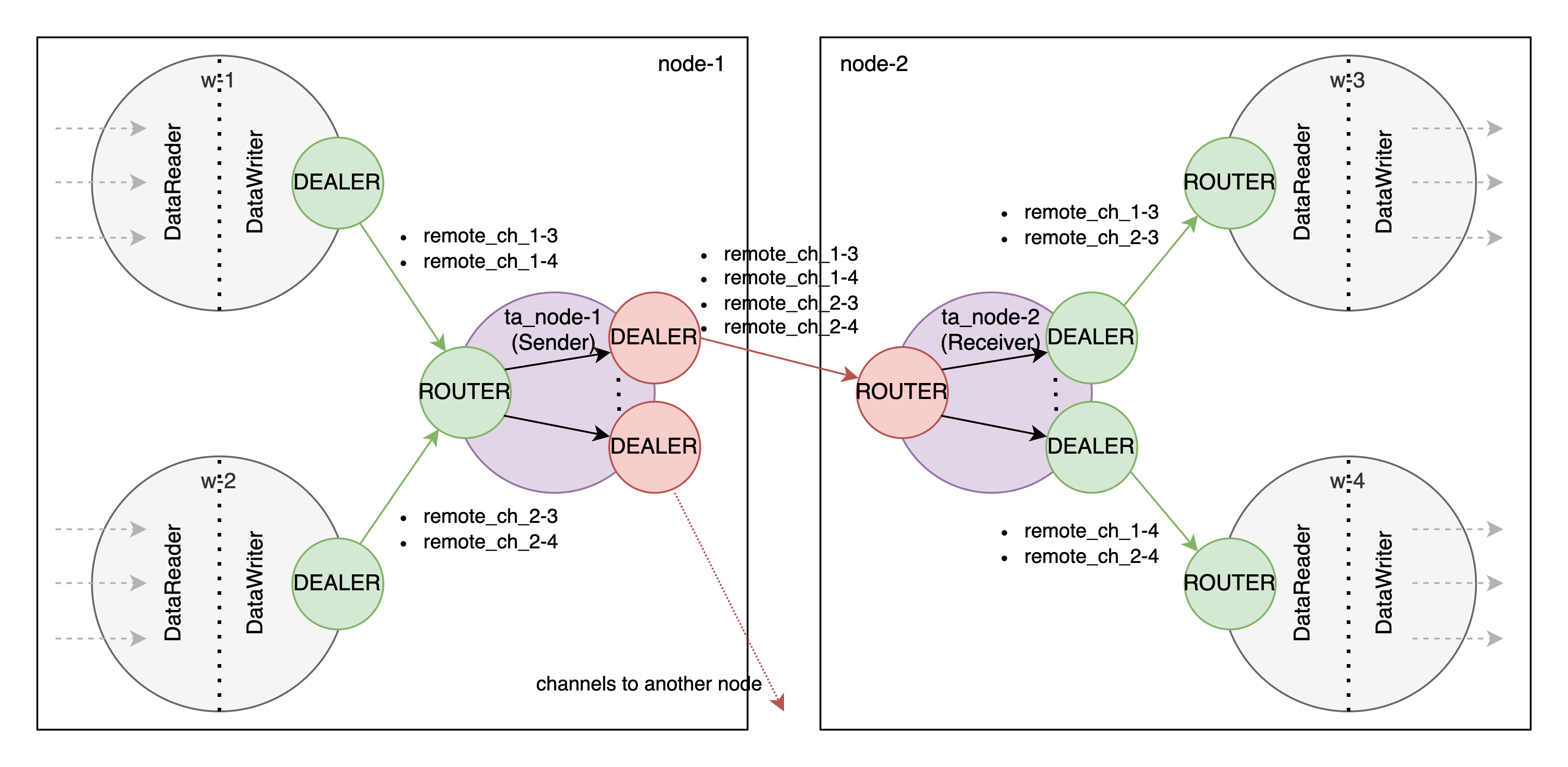
Smart messaging patterns. ZeroMQ provides different socket types (PUB<->SUB, REQUEST<->REPLY, PUSH<->PULL, etc.) which can be used to implement various messaging patterns. For our system DEALER<->ROUTER pattern was extremely helpful to easily route messages to correct receivers without re-implementing the whole routing logic from scratch.
How? A little bit about DEALER<->ROUTER sockets. In short, they allow for an asynchronous bi-directional request-reply communication between processes with a built-in routing mechanism (ROUTER knows where the data came from and who to reply to). All of the nice stuff ZeroMQ provides comes for free: connection handling and callbacks, socket identities, pluggable transport (IPC for in-node transfers and TCP for intra-node transfers), resources cleanup, etc., you can read more here.
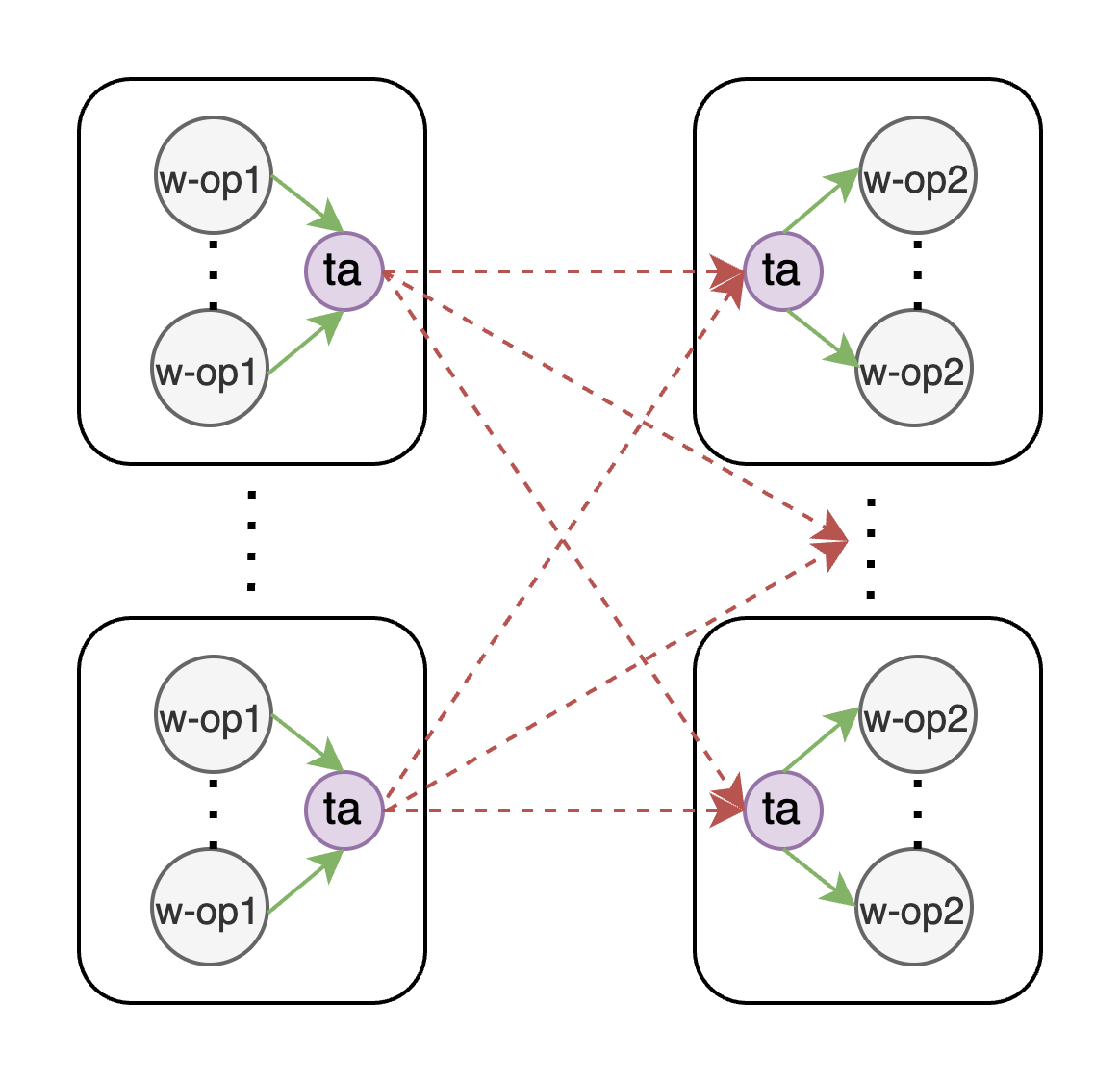
To make sure we are able to handle any job graph topology Volga's networking stack requires a full NxN peer-to-peer (worker-to-worker) bi-directional connectivity. To achieve this, we rely on a variation of Harmony pattern (which you can read more about in a O'Reilly book "ZeroMQ: Messaging for Many Applications", page 452): each reading peer binds a single ROUTER socket for all incoming connections and multiple DEALERs (one per peer) for each outgoing connection (our case is bit more nuanced with the usage of shared channels via custom TransferActors, which will be explained further).
Rust Networking Layer Overview (crossbeam channels, I/O threads, IOLoop, async comms)
While Python networking layer (described in the previous post) contains mostly simple logic wrapping PyO3 handles (and some aux functionality like batching and ser/de), the main networking happens in Rust. Each of the mentioned network interface objects (DataReader/DataWriter and TransferSender/TransferReceiver) have their own Rust representation where the actual magic happens (internally these objects implement IOHandler trait, so we'll call them IOHandlers).
The key peace of processing logic is IOLoop - the loop that continuously polls all the sockets of registered IOHandlers and reads/writes data whenever they are ready. Since ZeroMQ sockets are not thread safe, this allows for an easy way to poll all of the sockets from a single thread, utilizing async nature of ZeroMQ and offloading all of the CPU intensive processing logic (ACKs, watermarks, buffering, bytes manipulations) to a corresponding IOHandler via crossbeam channels. Each IOHandler has two threads - one for input data and one for output, so we always process everything asynchronously. This helps us avoid spawning large number of threads (forget thread-per-socket) and minimize context switching/locking overhead.
Reliability Protocol
Since intermediate TransferActor (described in the previous post) is stateless and can potentially be put down by forces outside of our control (e.g OOMKiller, random crashes, etc.), we rely on high-level agreement between sender and receiver (which can be anywhere: on the same node or a different node in the cluster). ZeroMQ also does not provide any delivery guarantees except for whatever underlying transport offers.
To ensure reliability Volga uses custom TCP-like protocol using ACKs (acknowledgment messages), watermarks, retries and buffering, all written in Rust.
For all messages buffered for sending in DataWriter's buffer we send a copy of a message along with it's ever increasing id and mark it as in-flight, number of in-flight messages is limited by a buffer size (or can be configured). When DataReader receives the message it checks the id and compares it with a current high watermark (max id received so far) to make sure we have no lost messages.
To ensure the ordering of arrival, we put the message in an intermediate store (in-memory) and move to output queue only when we have ordered messages. Only after the messages are inside DataReader's output queue (which is shared for all the channels) we send ACKs back to the sender (which can be configured to be batched to increase perf).
Upon receiving an ACK (or a batch of ACKs), sender removes the corresponding messages from in-flight and also pops the input queue, this unblocks writer to receive more data from the outside. This allows us to naturally perform backpressure if readers are slow to read data or go down. If a writer does not receive an ack for a given message within a configured timeout it simply resends the message.
This protocol allows us to reliably send data across different kinds of transport (IPC/TCP/UDP or multi-hop e.g. IPC+TCP) without losing messages while maintaining asynchronous flows of data and ACKs and keeping throughput and latency under control.
Backpressure, shared channels and Credit-based Flow Control
Described simply, backpressure is a mechanism to make sure the rate of data production at the source of the pipeline is synchronized with the rate of data consumption at sink so the whole pipeline stays stable and efficient (no memory overflow, no wasted time/resources at source/sink, etc.). There are many ways to implement it in a distributed messaging systems each having it's pros and cons - here is a good post with an overview of different techniques.
As described above, Volga relies on buffering and message ACKs to implement flow control and naturally performs backpressure for channels with overproducing writers. This approach is straightforward and is relatively simple to implement, however it has certain drawbacks in our context.
As mentioned previously, our design uses shared connections (or multiplexing) to send data over channels originating on the same node (via TransferActor on this node). This means that if one of these channels starts to backpressure, it will also block all of the other channels using this TransferActor even if their rate of production and consumption is working well. This is obviously not ideal as the whole pipeline will perform as it's slowest writer-reader pair.
This problem is not new and Flink had a similar problem. Their solution was to implement a Credit-based Flow Control - each reader announces how much it can consume at any given moment to writers and writers send exactly this amount. One of the next steps for Volga is to implement it as well.
A small personal note on development history
Developing good software is hard. Developing a real-time distributed fault-tolerant system aimed for low-latency and high-throughput data processing is extremely hard.
The current version of networking stack is a result of multiple prototyping iterations, trials, errors and unsatisfactory performance. To pay due respect to all of the work put in, here is a small description of the iterations done:
The initial version aimed at keeping everything as Python as possible. No Rust was used, only PyZMQ lib to interface with the network. While it worked, the approach was pretty naive and did not show any scalability in distributed setting, had no way of controlling such things as backpressure, multiplexing etc. and had no delivery/reliability guarantees.
The second iteration was an attempt to copy Flink's network topology - this is how current architecture with TransferActors was born. On Python side the decision was made to use asyncio (which PyZMQ supported) with plain PAIR sockets. The first version of reliability protocol was implemented. While this scaled well, the performance was still extremely poor (multiple magnitudes lower throughput and higher latency then what we have now).
The third version was the introduction of Rust layer - re-write of the reliability protocol and move of all the ZeroMQ stuff to Rust. This showed great improvements, but still had certain bottlenecks - mainly due to initial decision to use socket-per-channel model which did not scale well.
The fourth version is the current version of what has been described here - remote channels sharing sockets, all-Rust networking layer, stateless TransferActor.
On a personal note, as author, I'm greatly thankful to you, reader, for taking your time to get familiar with this work and getting this far. The main driving force behind this effort is pure engineering curiosity and enthusiasm (with a fair pinch of ambition that this project will grow to see some adoption), so any feedback you may share is worth its weight in gold to me and may help me go the extra mile with the project.
Now for the fun part, check out part 3 to see how Volga behaves in real life: numbers for throughput (million messages per second), latency and scalability for different use cases - from a laptop to a 100+ CPU Kubernetes cluster.