
Volga - Streaming Engine and Networking - Deep Dive - Part 1
Designing a distributed networking stack for real-time, high-throughput and low-latency streaming engine from scratch. Part 1.


TL;DR
Volga is a hybrid push+pull data processing/feature calculation engine for real-time AI/ML systems. It is designed to allow you to easily build your own real-time ML feature platforms or general data pipelines without relying on heterogenous data processors (Flink/Spark/custom data processing layers) or third party services - you can read more about motivation here. Volga provides native Python runtime and is built on top of Ray - more about high level design and API here.
Volga Streaming is a custom streaming engine used for streaming data processing and is the first of the two main parts of the whole system - the push part. (The second one, the pull part is not covered here).
In this 3-post series we will make a deep dive into Volga's streaming engine internals focusing on it’s main moving parts and networking stack behind it.
This post covers high-level design of the streaming engine and it’s building blocks, optimizations and network topology.
The second part goes deep into low-level networking stack (Rust and ZeroMQ, Communication and Reliability Protocol design, Backpressure mechanics and more).
The third part is a scalability and performance benchmark where we scale Volga to a million messages per second and 100+ CPUs Kubernetes cluster.
Content:
What a Streaming Engine is and what it is for
Quick Overview of Streaming Engine internals
Network Topology and Communication Primitives
Worker-Node Assignment Strategies
Python Networking Layer Overview (batching, serialization, threading model, per-worker API)
What a Streaming Engine is and what it is for
Modern services that we use everyday rely on real-time data to function: calculating order delivery ETA (estimated time of arrival), detecting credit card fraud, forecasting ride demand for proper pricing and ETA, ranking search results, recommending relevant content on marketplaces and social media, etc.
Streaming Engine is a the heart of those systems transforming raw user data (clicks, views, ride requests, delivery orders) into an actionable input for decision-making modules of the system (static rules or ML models) as soon as it arrives, at scale, with low latency and high durability. All of the modern data platforms for real-time AI/ML (Tecton.ai, Fennel.ai, Chalk.ai) rely on a streaming engine (Spark Structured Streaming, Flink or a custom solution) under the hood.
An example of one of the most common streaming workloads in real-time ML systems is continuously calculating counters - number of clicks of a certain type (e.g. likes, comments) made on a given post in the last minute, number of transactions above a certain threshold a user has made in the last hour/month, etc. These counters are later used as features for ML models (e.g. ranking algorithms in recommendation systems, fraud/anomaly detection models, etc.). The job of a streaming engine is to transform raw input data (user clicks/likes/transactions, car ride requests, food orders) from the outside source (e.g. Kafka) in real-time into the aggregated result and put it in the storage (e.g. Redis or ScyllaDB) for ML models to read/retrieve.
Reading these values at ML model inference time and transforming them in a proper way (the process called feature retrieval) is also not a trivial task - there is a time discrepancy between when the aggregation was made by the streaming engine and when the actual request for those aggregates was made by the inference service, this directly impacts model’s output (this is why Volga also has the pull part of the system, but this is not the focus of this post).
Quick Overview of Streaming Engine internals
Volga Streaming uses Ray Actors as independent streaming workers (in Flink world those would map to subtasks). Each worker is an independent Python process, orchestration happens via Ray which provides a set of powerful tools to create a distributed Python-native system: scheduling/resource allocation API, Python runtime environment management, non-latency sensitive actor-to-actor communication, Kubernetes integration, etc.
Workers are logically grouped into Operators - independent stateful or stateless transformations on a finite or infinite stream of events, consuming 0 (Source) or more input streams and producing 0 (Sink) or more output streams. Example Operators are Map, Join, KeyBy, Reduce, Window, Aggregate, etc.
Parallelism of an Operator is a number of workers independently executing it's logic.
A Streaming Job is a DAG (Directed Acyclic Graph) of Operators compiled from a high-level user-defined DataStream object (Volga's streaming pipeline definition API is very similar to Flink's DataStream API)

The way sequential Operators distribute messages between instances of each other's workers is called a Partition. Depending on Operator's type we can have different partitions. Two most commonly used are:
ForwardPartition (when parallelisms of two operators are equal, each worker of one operator simply sends messages to another's worker at the same level/index)
KeyPartition (based on a key from each message extracted by user-defined function, each message is mapped to a specific peer worker so all messages with the same key end up in the same worker, this is necessary for operators with key-based aggregations - Joins, Windowed Aggregations, etc.).
Other examples include RoundRobinPartition (each worker round-robins to peers), BroadcastPartition (each message is sent to all peers) and more.

ChainedOperator or Operator Chaining is an optimization when two logical Operators with the same parallelism and appropriate Partition strategy between them (ForwardPartition) can be combined into a single operator. This drastically improves performance in certain cases as all of the computations are done directly in-memory. Volga has chaining implemented and turned on by default, although this can be disabled if need be.

It's worth noting that all of the above is a simplified version of how runtime execution works and does not take into account such things as checkpointing, persistent state, out-of-order data handling and watermarks, failover/recovery, automatic rescaling, etc. (which are extremely important for production workloads but are not the focus of this article).
Network Topology and Communication Primitives
Channel is a logical connection between two workers (processes), each worker can have multiple input and multiple output channels. If workers are on the same node the channel is an instance of LocalChannel which represents a simple IPC connection. If workers are on different nodes we have a RemoteChannel which represents a multi-hop connection where data goes through transfer/routing processes (called TransferActors) on each node and shared TCP connections before reaching destination.
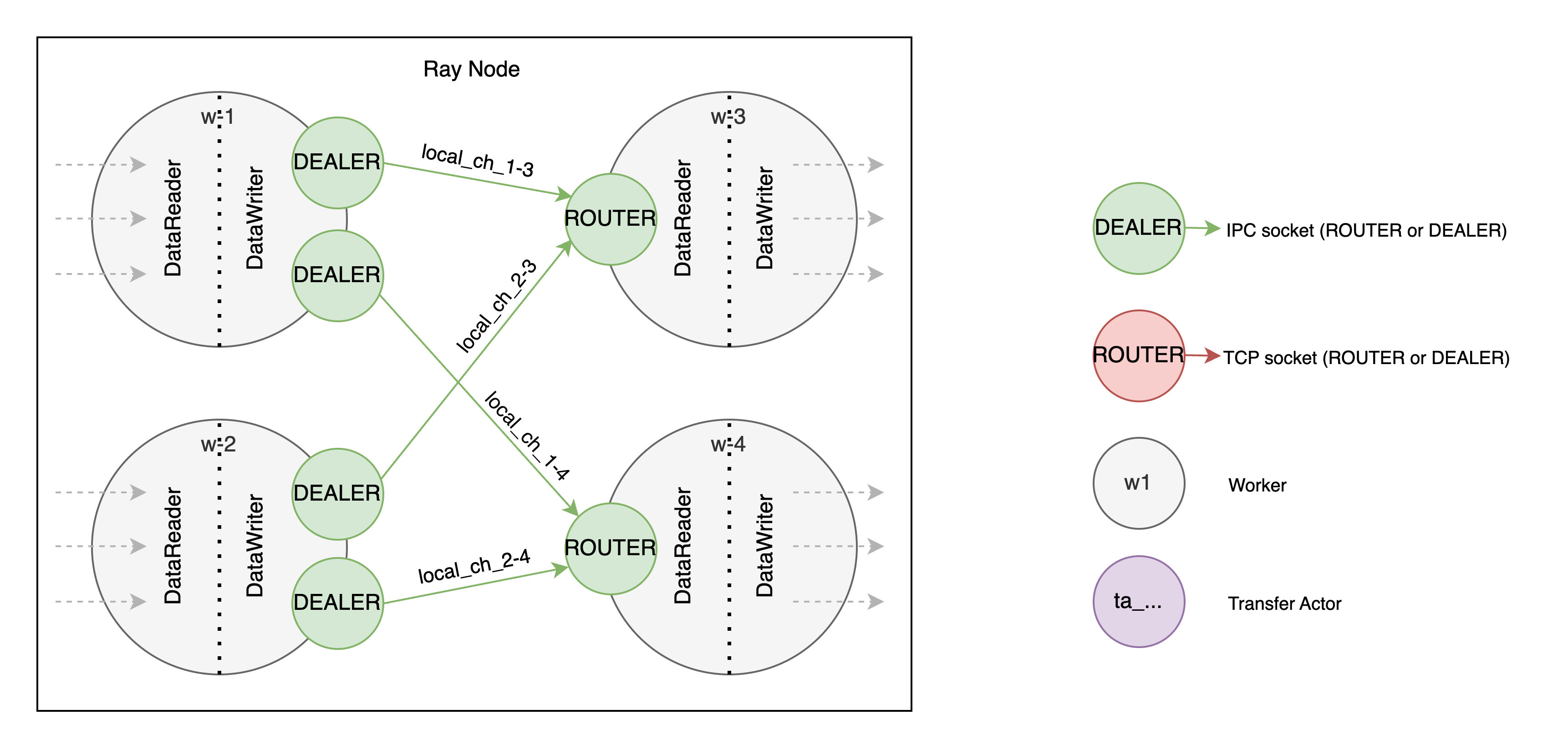
DataWriter is an interface object used to send messages to a desired destination (based on channel id). DataReader is an interface object used to read received messages from all channels a given worker is subscribed to. These two essentially form an API for a distributed multi-producer multi-consumer queue (for DEALER and ROUTER socket explanation see the second part).
Each worker has an instance of both DataReader and DataWriter (exceptions are source workers - no reader and sink workers - no writer). Both DataReader and DataWriter can operate on both LocalChannel and RemoteChannel instances simultaneously, this depends on job topology and how workers are assigned to nodes. High-level execution flow of a single worker is simple: read a message from DataReader, perform computation, write result to DataWriter.

TransferActor is a process simultaneously running TransferSender and TransferReceiver - objects responsible for sending data from local DataWriters to remote peer nodes (TransferSender) and passing data from remote peer nodes to local DataReaders (TransferReceiver), it comes into play only when we run Volga in distributed setting (more then one node). It's role is to connect to all workers on the node, hence TransferActor operates only with RemoteChannels. Each node in a cluster has exactly one TransferActor. DataWriters/DataReaders communicate with TransferActor via IPC connections (one per process), TrasnferActors on different nodes are connected via TCP connection, all of the remote channels share these connections (both IPC and TCP, based on job topology). TransferActors are stateless - they are designed to be easily restarted in case of failure, all of the reliability issues and delivery guarantees are a matter of our custom higher-level data exchange protocol (covered in the second part).
If you are familiar with Flink you can notice that the whole stack is very similar to what happens inside of it's networking layer, the only difference is that we have processes rather than threads as workers (because Python) and hence data between them is shared via IPC rather then in-memory data structures.
Worker-Node Assignment Strategies
Another critical part which impacts overall engine performance is how we assign workers to nodes. Once Volga compiles user's DataStream object into an ExecutionGraph (DAG made of actual Python workers) it needs to decide how to map workers to physical nodes/machines in the cluster - this logic is incapsulated in NodeAssignmentStrategy. Depending on NodeAssignmentStrategy type and what kind of machines are used we can have different effects on throughput and latency. Volga has two out-of-the-box strategies: ParallelismFirst and OperatorFirst (however the framework is extensible and users can come up with their own logic).
ParallelismFirst - greedily maps workers onto a node iterating over parallelism first (hence fixing it for a given node). This way workers belonging to different operators end up on the same node which minimizes network communication and mostly relies on local channels (inter-proc). This is a good strategy when your cluster is made of bulky instances or when a network bandwidth is a bottleneck.
OperatorFirst - this is an inverse strategy iterating over operators in a DAG first, this way we have nodes contain workers belonging only to a single operator, without sharing operators (i.e. one node - workers of one operator only). This strategy is useful when your cluster is heterogeneous w.r.t. node perf capability or simply is made of smaller instances and you want to spread the load more evenly (in this case a lot of communication will go over network, hence it is expected not to be a bottleneck)

Python Networking Layer Overview (batching, serialization, threading model)
As described above, network interface objects are used by streaming workers to read data from DataReader, perform computations and write output messages to DataWriter, all of that happens inside a Python interpreter (worker). Let's take a closer look at what happens down the stack (but still at Python level).
Batching. One of the most important performance optimizations is batching messages together and sending them down to network all at once, this significantly improves engine's throughput (trading-off with latency). Once a batch reaches certain size (configured by user) it is sent down to Rust layer via PyO3 interface (more in the second post). There is also a flusher thread which periodically flushes incomplete buffers if timeout is reached.
Serialization. While Python side operates with fixed data models (Messages), underlying Rust interface expects data to be serialized as bytes and also reads it as bytes. Volga uses msgpack which has demonstrated to be the most performant ser/de library in our benchmarks. In conjunction with batching we have a significant perf increase (compared to per message ser/de)
Threading model. The main read-compute-write loop is executed in a single thread, DataReader and DataWriter are blocking by default (to allow backpressure) but release GIL and are used only from this thread, this allows other I/O-bound threads (e.g. flusher) to perform without delays. None of the CPU intensive GIL-holding work is done in other threads (so we essentially comply with Python's single-threaded CPU bound model), this makes sure we do not have perf degradations on Python side. All of the PyO3 binding are also configured to release GIL while doing CPU-heavy stuff.
While this layer contains simple logic wrapping PyO3 handles (and some aux functionality like batching and ser/de), the actual low-level networking happens in Rust with the help of ZeroMQ, which is described in the second post.
This is the end of the first part. The second part covers how we utilize Rust and ZeroMQ, Reliability Protocol design, Backpressure mechanics and more. For scalability, performance and running Volga on distributed Kubernetes cluster (EKS) see the third part.