
Volga - On-Demand Compute in Real-Time AI/ML - Overview and Architecture
Exploring use cases and architecture for Volga's On-Demand Compute Layer

TL;DR Volga is a real-time data processing/feature calculation engine tailored for modern AI/ML. It is designed to support various types of features, including streaming (online), batch (offline), and on-demand features, via a hybrid push+pull architecture: a custom Streaming Engine (for online+offline) and an On-Demand Compute Layer (for on-demand). In this post, we will dive deep into the on-demand compute layer, on-demand features, use cases, and architecture. For performance evaluation and benchmarks see this post.
Content:
What it is and what it is for
Examples
Architecture
API Overview
A missing part of the Ray ecosystem
How Streaming and On-Demand work together
Next steps
What it is and what it is for
Most real-time systems operate on streams of events (e.g. user clicks/purchases, ride requests, credit card transactions, etc.) and represent a fully event-driven system: all data transformations/custom logic can be somehow tied to an event that triggered it, and that is true for any part of the system. These kinds of systems can be handled by a stream processing engine alone.
ML workloads are a bit different: they belong to a class of request-based systems (in our case, we talk about model inference requests). This class of systems includes most modern web applications, whose architecture is based on the request-response model and built using the notion of a server (or a web service).
Generally speaking, the request-response pattern can also be transformed into a purely event-driven system where each request is a separate event (this is a good design direction to explore). However, in practice, request-based systems are usually stateless and have different requirements for scalability, latency, throughput, data availability and fault tolerance, resulting in a different infrastructure stack requirements compared to what a streaming engine offers.
As a result, in the context of real-time data processing and feature generation, most ML-based systems require a layer that would be able to process incoming requests with minimized latency, perform arbitrary computation logic, and serve results as soon as possible so it can be used in other parts of the system (e.g. model serving) or directly by the user—this is what we call the On-Demand Compute layer.
Examples
Some examples of real-time ML systems that require on-demand request-time computations and cannot rely only on a streaming engine alone may include:
A search personalization system which relies on a user's GPS coordinates: the data is available only at request-time and should be handled immediately for relevant results.
A recommender system, where responses rely on an expensive computation (e.g., embedding dot product, GPU-based operations, etc.) and/or communication with 3rd party services (e.g., querying another model)—handling this in a streaming engine would create a bottleneck and would require a very careful design.
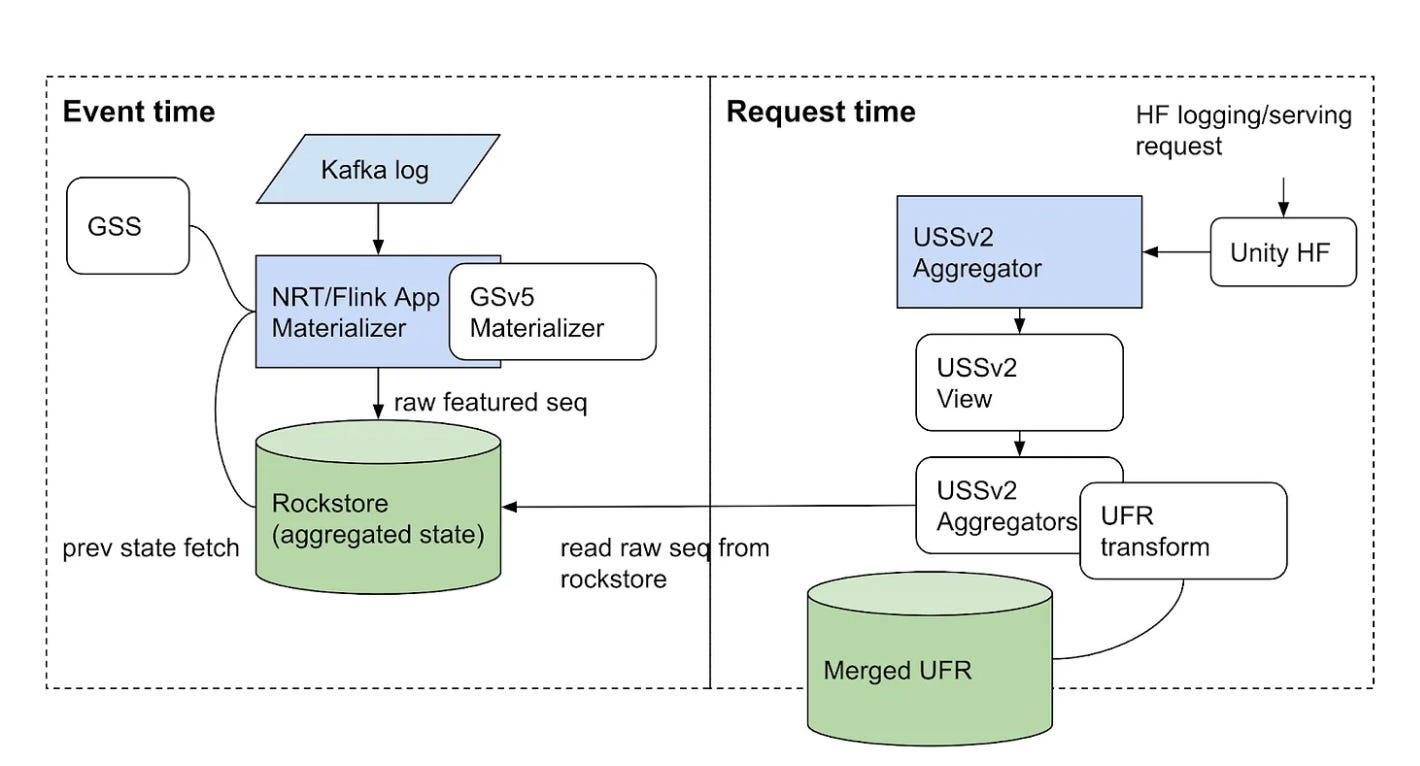
This is the part that many "AI/ML-ready" streaming engines miss: event-time processing alone is not sufficient to cover all real-time AI/ML needs. For that reason, Volga separates its architecture into the Push Part, where the Streaming Engine is the king, and also introduces the Pull Part, handled by the On-Demand Compute Layer, where request-time compute is done.
Most modern ML feature/data platforms adopt a similar architecture (On-Demand features in Tecton, Feature Extractors in Fennel, Resolvers in Chalk).
Another good example is Pinterest's Homefeed Recommender System's Real-Time Feature Pipeline, which also has a separation between event-time compute, handled by a streaming engine (Flink), and request-time compute, handled by a custom service.
Architecture
In summary, in Volga, the On-Demand Compute Layer is a pool of workers used to execute arbitrary user-defined logic (what we call an on-demand feature) at request/inference time and serve it back to the user. It is built to be interoperable with Volga's Streaming Engine, so the whole system can run arbitrary computation DAGs that include execution at both event and request times. Let's take a look at the working parts of the system and the request lifecycle.
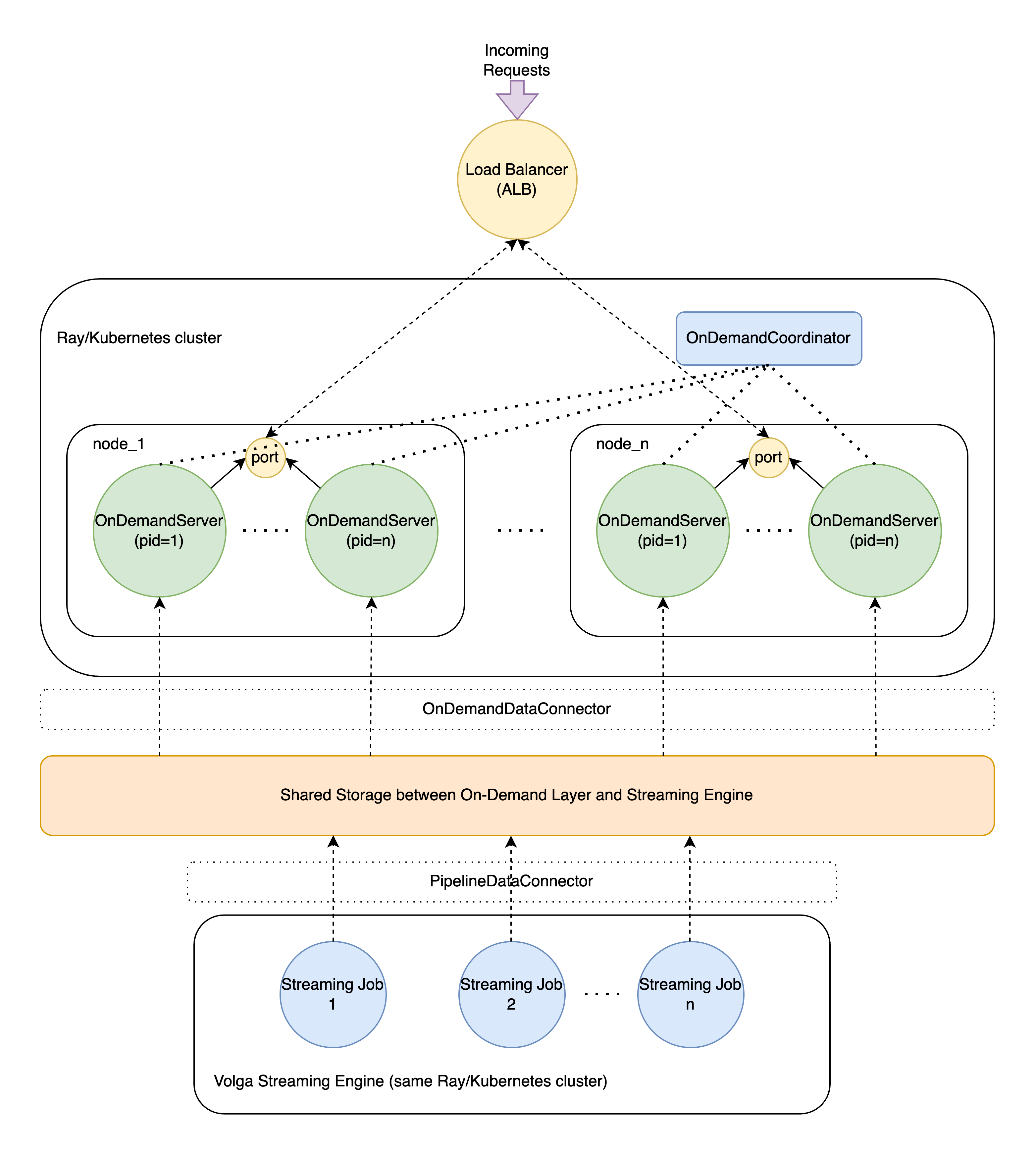
OnDemandCoordinator This is the first component that comes into play. The
OnDemandCoordinatoris an actor responsible for orchestrating and trackingOnDemandServers—worker actors (more below). TheOnDemandCoordinatorhandles logical worker isolation (configuring which features each worker is responsible for), scaling up and down, health checks, and restarts if needed.Load Balancer The outside component that handles incoming requests and distributes them among cluster nodes. This is usually a cloud-based resource (for our benchmarks, we used AWS Application Load Balancer), but in practice, it can be any other setup (e.g., Nginx/MetalLB). Note that the Load Balancer is not a part of Volga and represents a most likely deployment pattern.
OnDemandServer A Python worker that performs logic described in on-demand features. The worker process runs an instance of a Starlette server to handle incoming requests, each listening to a fixed port on a host node. This way, the OS (Linux only) round-robins all the requests to workers on that node, keeping the load balanced.
Each worker is initiated with a list of feature definitions that it is supposed to handle (initiation is handled by the
OnDemandCoordinator). When a request arrives, theOnDemandServerparses which target features it is supposed to execute and compiles a DAG of all dependent features. Remember that Volga supports two types of features:on_demand(handled by the On-Demand Layer) andpipeline(handled by the streaming engine).Since the most powerful aspect of Volga is that it supports both event and request time compute,
on_demandfeatures can depend on both otheron_demandfeatures as well aspipelinefeatures. This fact creates a special execution flow: the features DAG is topologically sorted and executed in-order;on_demandfeatures are executed using their dependents' results as inputs. In the On-Demand environment,pipelinefeatures are treated simply as reads to storage: the end-to-end flow of Volga is that the actual execution ofpipelinefeatures is handled by the streaming engine, which writes pipeline execution results to shared storage asynchronously. The On-Demand worker simply reads the corresponding pipeline feature results (the way it reads it is also configurable inOnDemandDataConnector, more about it below) and uses it as input for on-demand logic.Storage The storage is an abstraction shared between Push and Pull parts: streaming jobs materialize pipeline results in the storage, on-demand workers perform asynchronous computations based on materialized data and serve results. Note that in the On-Demand environment, the storage is read-only (
on_demandfeatures do not need to store anything).The storage is a configurable interface, which can use an arbitrary backend (via implementing
PipelineDataConnectorandOnDemandDataConnector). Note that since we can run Volga in both online and offline modes, each mode has different storage requirements, e.g. online requires minimizing read/write latency (Redis/Scylla), offline is for capacity-optimized store (HDFS, lakes): this is something for the user to consider.
API Overview
On-Demand features are created using the on_demand decorator and can depend on pipeline features or other on_demand features.
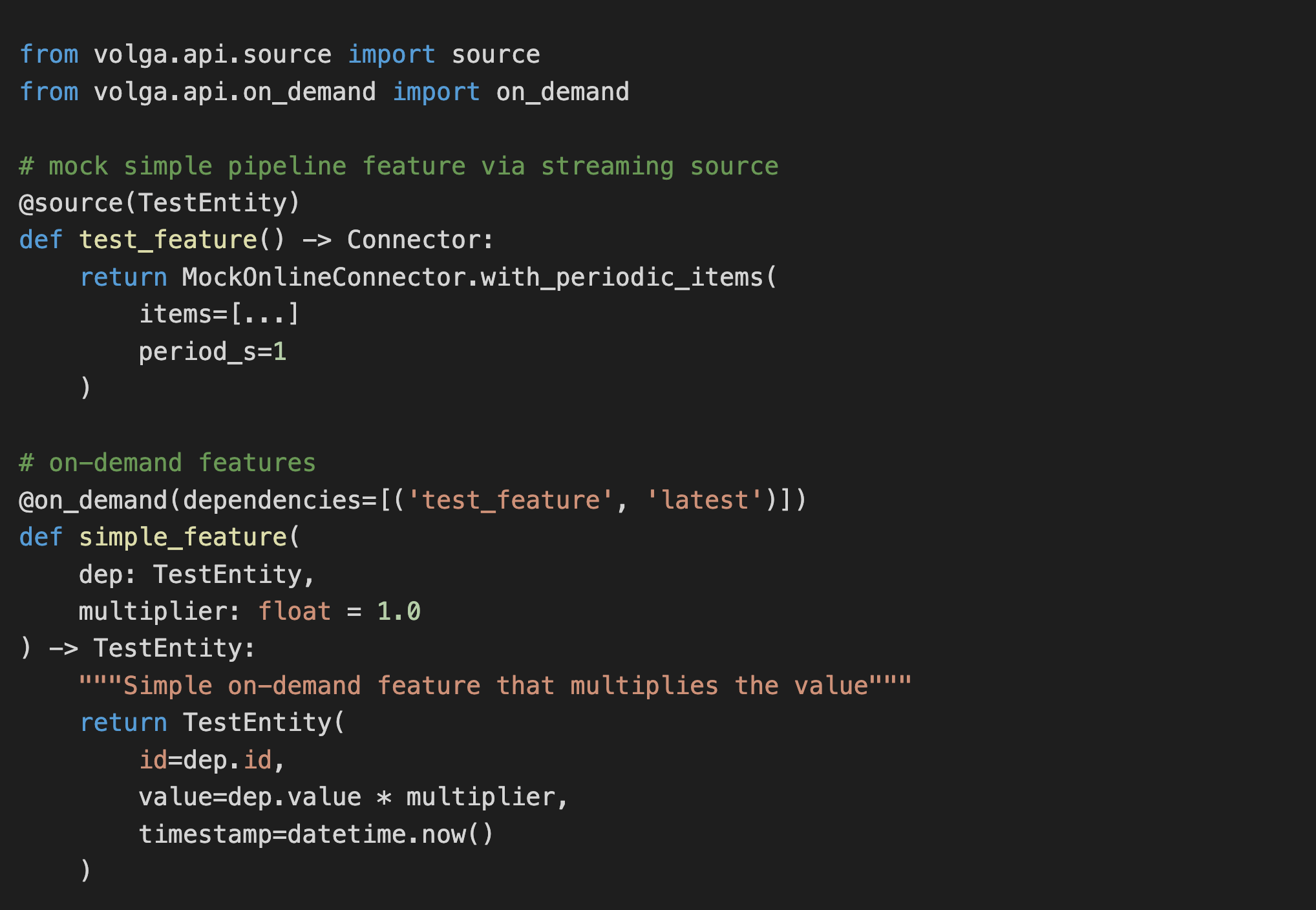
The dependencies parameter describes the dependent features; the order should match the corresponding arguments in the function. Note that dependency is a 2-tuple: the first value is the name of the dependent feature, and the second is the query_name defined in OnDemandDataConnector (MockDataConnector in our case): it defines how we fetch values for test_feature - in this case, we simply fetch the latest (more about data connector queries below).
Start workers and register features to serve:
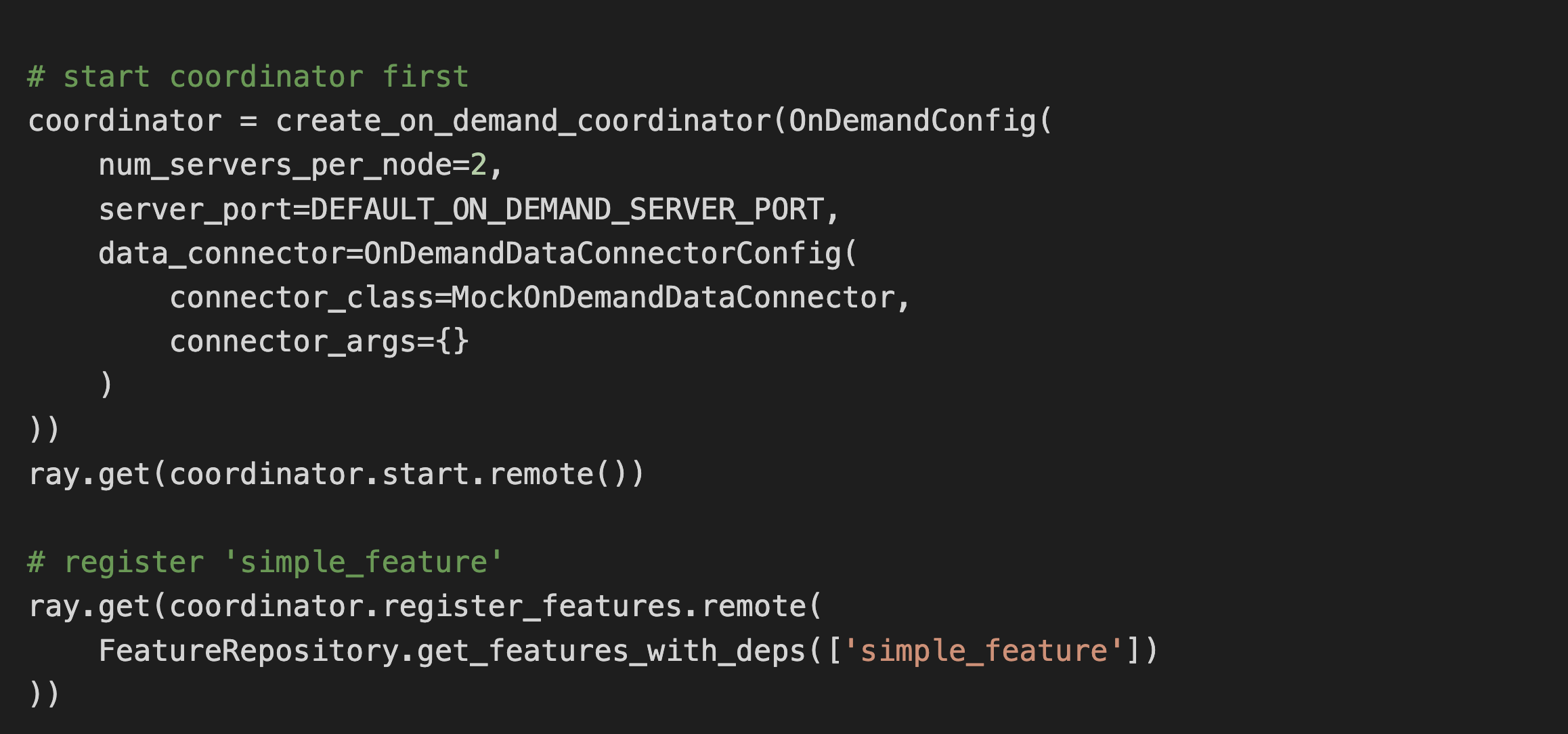
Compose a request using required keys and query features in real-time:
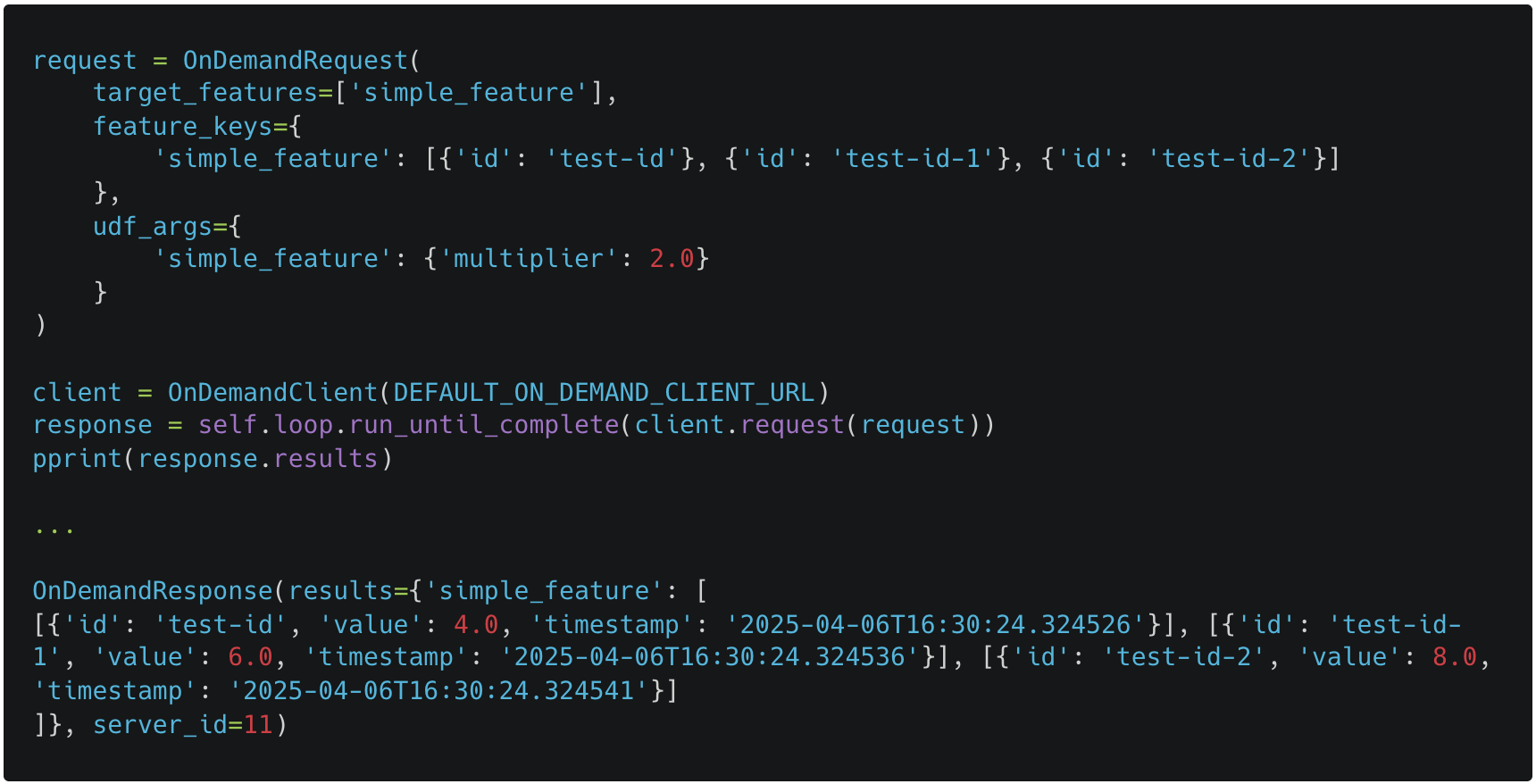
A missing part of the Ray ecosystem
A careful reader may note that the On-Demand architecture somewhat resembles that of Ray Serve (model serving infrastructure used by Ray). Indeed, both systems are request-based and are complementary to each other, as both systems represent vital parts of the end-to-end model inference flow: getting features first and then using them for actual inference.
While Ray provides the model serving part, feature serving/calculation is missing, requiring users to rely on custom data serving layers, which significantly increases complexity and operational costs of running real-time ML.
The On-Demand Layer is designed to fill this spot and, along with model serving, to become the initial user-facing frontier for modern ML-based systems. This will help to move towards a more homogeneous system design, removing outside dependencies and, with Volga's Streaming Engine, unifying real-time data processing on top of Ray.
How Streaming and On-Demand work together
This section discusses the shared storage between the Streaming Engine (Push) and On-Demand (Pull) parts and how the On-Demand layer interfaces with it. All of the on_demand features directly or indirectly depend on pipeline features' results, which exist in shared storage (this includes simply serving pipeline features). To simplify the feature definition API and hide the data layer control from the user, the decision was made to abstract all storage-related data fetching logic from the actual feature logic into a separate class that can be reused across different features: OnDemandDataConnector (see the Architecture diagram above).
Since pipeline jobs can produce semantically different results, the way we fetch data for on_demand features should also be configurable to reflect this semantics, e.g. some features need the most recent values, some need to window data until a certain period, some need to perform more complex queries like nearest-neighbor search (RAGs). Let's take a look at InMemoryActorOnDemandDataConnector used in the local dev environment (represents an interface with InMemoryCacheActor):
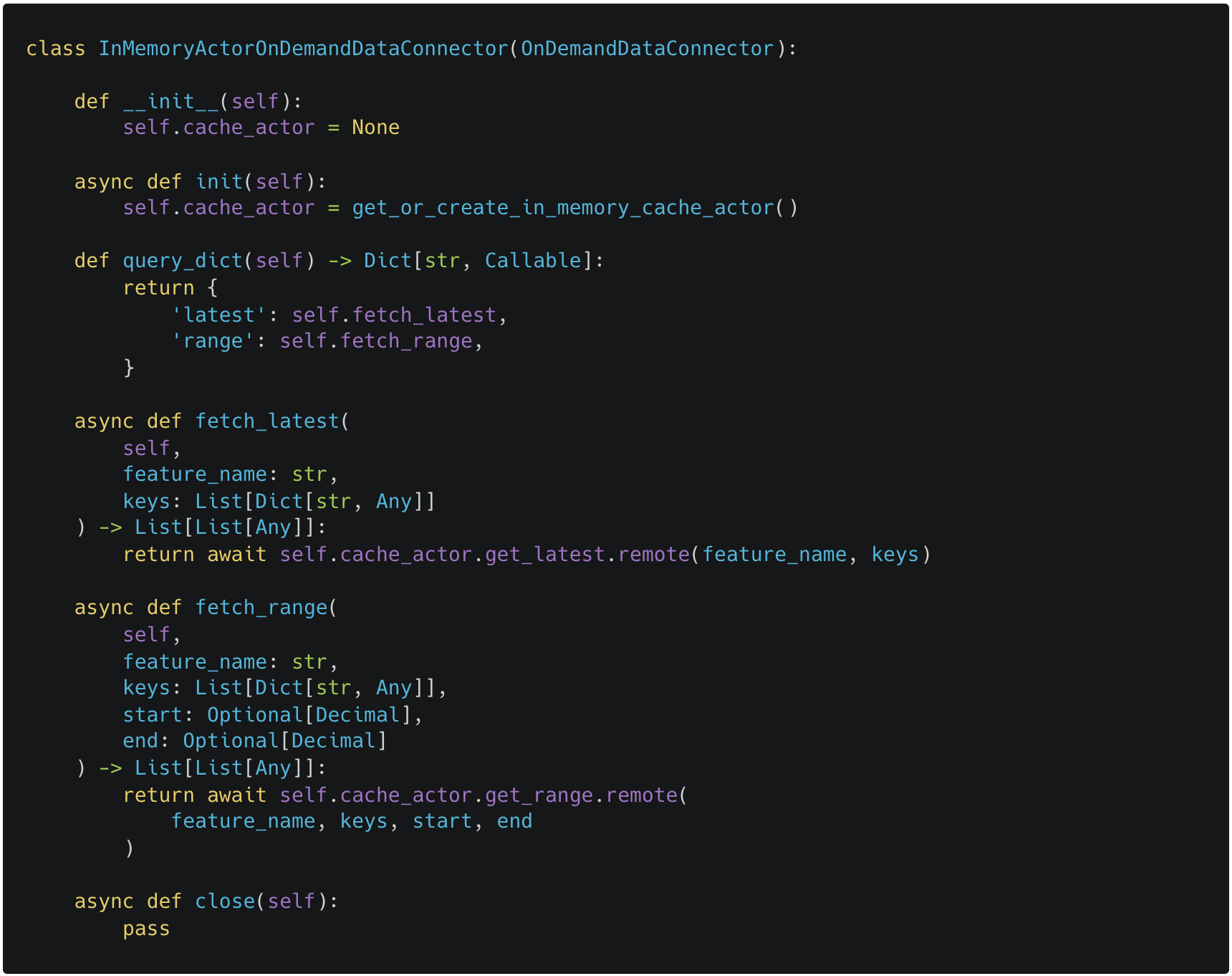
The core method that the user needs to define is query_dict: It maps an arbitrary fetching function to a simple name that we pass to the on_demand decorator when creating features (remember the latest param in the sample_feature example above). Arguments passed to these functions are parsed from the request object using the same arg names as keys.
This separation of data fetching from feature logic allows for much cleaner and reusable code, as well as safe, controlled, and optimized access to the data layer—user-defined code won't be able to hammer the storage or do anything indecent.
Next steps
On-demand features currently work only in online mode; Volga does not support calculating on-demand features on historical data. This is an interesting engineering problem that requires turning request-response-based systems into an event stream (suitable for offline mode) and building a streaming pipeline to fully execute on the streaming engine.
As you may have noticed, on-demand features get general parameters and data connector parameters from the user's request. What if we want to get those from the dependent feature? This will require creating an
arg_mappingto map arguments to functions and updating the executor ordering logic.Some on-demand features may require local state (e.g. initializing a client for a third-party service).
Fault tolerance with health checks and restarts needs to be implemented.
Current execution is on an asyncio loop; a thread pool and process/actor pool are needed.
If you are interested in helping with these and becoming a contributor, check out the RoadMap and feel free to reach out!
Check out the second post, where we run load-testing benchmarks on EKS and Ray with Locust and Redis and show how the On-Demand Compute Layer performs under high request load.
Thanks for reading! Please star the project on GitHub, join the community on Slack, share the blog and leave your feedback.